Postprocessing
Comme dit dans un billet passé, j'ai acheté un scanner avec un chargement automatique de document (ADF) après avoir lu un commentaire qui en vante la praticité sous un billet de David Madore sur la gestion paperasse.
J'avais déjà un scanner à plat depuis presque dix ans, mais son utilisation était manifestement trop pénible pour empêcher la croissance de mes piles de papiers à scanner.
J'ai dû faire violence à mon impression de ne pas avoir besoin d'un scanner de plus, et qu'un petit effort suffirait à se satisfaire du scanner à plat, parce que j'ai suffisamment de papiers à scanner pour que le gain de temps soit justifié même si je ne recevais plus jamais de papier de ma vie.
Une fois l'ADF en ma possession, le premier problème a été de faire en sorte que mon ordinateur de bureau Tsuiraku communique avec lui, qui est ce que j'avais expliqué dans le billet intitulé Bricolage.
Une fois la première image scannée, je croyais être au bout de mes peines, il ne restait plus qu'à écrire le script qui assemble les images scannées dans un PDF et le tour aurait dû être joué. Et puis j'ai découvert l'image produite…
Voyez plutôt :

C'est une mire que j'avais imprimée pour diagnostiquer des soucis avec mon imprimante laser couleur (qui se trouve être combinée à mon scanner à plat), et elle contient des damiers de différentes couleurs et de différentes tailles.
Échelle d'intensités
La première chose qui m'a interpelée, c'est le bruit général de l'image, mais j'y reviendrai plus tard.
La deuxième chose, c'est à quel point le fond est sale, ou en tout cas pas blanc comme la feuille.
En dessous de la mire, il y a une zone bleue, que j'ai fait exprès d'inclure dans le cadre ci-dessus, parce que c'était justement une partie du problème d'imprimante. Donc cette zone bleue est bien là sur l'original, mais beaucoup beaucoup plus pâle.
Du coup j'ai regardé de plus près le reste du papier à peu près blanc, tout est correctement détecté par le scanner, mais étonnamment amplifié par rapport à ma perception du papier scanné.
Alors j'ai essayé de scanner la même mire dans mon scanner à plat, et l'image qui en sort est similaire à ma perception du papier, et en poussant sur les niveaux je suis arrivée à retrouver quelque chose qui ressemble beaucoup à mon image fautive.
J'ai donc essayé de fabriquer la transformation inverse, et après de nombreux échecs en cherchant une relation linéaire, j'ai eu l'idée de chercher une loi de puissance. Et la puissance était en gros de 2.1.
Cette transformation a fait resurgir de ma jeunesse la non-linéarité des écrans cathodiques, et du coup je me suis dit qu'en fait ce n'est peut-être pas un défaut de calibration du scanner, mais simplement des données RGB linéaire interprétées à tort comme sRGB.
J'ai donc ajouté une ligne d'ImageMagick dans mon script pour corriger ça, et le résultat est bien plus proche de ma perception.

Zone de scan
Une fois les couleurs corrigées, j'ai commencé à vouloir utiliser mon script pour de vrai, et un deuxième problème s'est révélé : le scanner ne respecte pas la zone de scan demandée.
Ça ne se voit pas tellement sur mes extraits ci-dessus, justement parce que ce sont des extraits pour afficher sur mon site.
Je n'ai pas tellement cherché à comprendre ce qu'il fait exactement, mais SANE prétend qu'on peut envoyer des fractions de millimètres pour demander une certaine zone à scanner, alors que l'image renvoyée par le scanner a une taille quantifiée par quelque chose de l'ordre du pouce.
Comme j'avais déjà ImageMagick dans mon script, je n'étais plus à ça près, j'ai ajouté un recadrage automatique à la quantité de pixels correspondant à une feuille A4 à 300 dpi.
J'ai choisi une résolution fixe parce qu'avec mon scanner à plat j'ai très rarement eu besoin d'une autre résolution. Et les rares fois où c'était le cas, c'était pour contourner des sites qui trouvaient que j'envoie des fichiers trop gros.
Alignement des couleurs
J'ai fait plusieurs scans sérieux avant de trouver inacceptable l'espèce d'aura colorée autour des transitions entre noir et blanc.
On peut la voir sur la mire, mais ce n'est peut-être pas flagrant parce que c'est une image censée être colorée, et les contours sont moins intéressantes que les objets. C'est beaucoup plus flagrant dans une zone de texte noir sur fond blanc :

Je ne sais pas à quel point ça se voit sur votre écran, alors voici un gros plan :
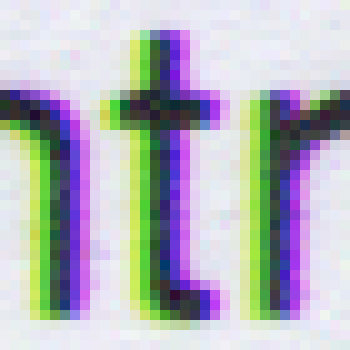
À chaque fois, c'est toujours le même halo : blanc, jaune, vert, noir ; et de l'autre côté noir, bleu, magenta, blanc.
Et l'un est symétrique de l'autre : le jaune est complémentaire du bleu, et le vert du magenta. Un peu comme si le plan bleu était décalé d'un pixel vers la gauche, et le plan vert d'un pixel vers la droite, par rapport au plan rouge au milieu.
L'avantage d'un déplacement de plans d'un pixel, c'est que c'est une transformation facile à faire de façon exacte. Le résultat n'est pas parfait, mais il se défend bien :

Il reste une légère composante verte sur la droite, mais ça reste plus subtil que le problème d'alignement vertical, lui-même inférieur au pixel entier. Du coup j'ai choisi de m'en contenter.
L'automatisation de cette transformation n'a pas été évidente du tout, mais j'ai fini par réussir à construire une transformation ImageMagick qui le fait. Au passage, le fait que le scanner envoie une zone trop grande se trouve être ici un avantage, parce que je peux recadrer après l'alignement des plans.
Je casse la chronologie ici parce que c'est bien plus tard que je me suis rendue compte que le problème décrit ne se pose que pour les rectos, et pour les versos il faut la faire dans l'autre sens. Ça ajoute un tout petit peu de complexité dans le script, mais je me demande surtout comment un tel problème peut survenir.
Un autre point qu'il faudra élucider à l'avenir est que ce problème d'alignement des plans colorés dépend de la résolution. Par exemple, à 301 dpi il n'y a aucun problème. J'ai été tentée d'utiliser cette solution, mais vu le temps de scan, le capteur prend 600 dpi et le firmware réduit la résolution avant d'envoyer l'image par USB.
Ça posera un problème intéressant lorsque je voudrai autoriser d'autres résolutions…
Redressement des pages
Je croyais naïvement que les rails de l'ADF suffiraient à toujours scanner droit, et ce n'est manifestement pas le cas, ou alors il y a quelque chose que je fais mal.
Je me demande si ajouter une plaque de quelque chose sur le chargeur, pour empêcher le papier de passer au-dessus des rails, peut aider. Ou au moins limiter le changement d'angle à chaque pli dans le papier.
Bref, ma ligne de commande ImageMagick est déjà monstrueuse et au-delà ce
que permet GraphicsMagick, je ne suis plus à un -deskew 40% près.
Détection des pages vides
L'inconvénient d'un scanner recto-verso, c'est que les documents n'ont pas tous de verso.
Quand aucun n'a de verso, je ne vais pas perdre du temps à scanner en recto-verso, c'est déjà bien assez lent comme ça.
Mais dans une série de pages recto-verso, il n'est pas rare que la dernière page n'ait qu'un recto, si le total a un nombre impair de pages.
Du coup j'ai ajouté un simple seuillage pour détecter et supprimer les pages vides.
Au début j'ai fait le test sur l'image finale, après réalignement des plans colorés et redressement et tout. Comme Tsuiraku est un peu poussif, je préfèrerais éviter tout ça sur les pages vides. Une conséquence est que le seuil doit être ajusté, parce qu'il sera fatalement différent en RGB linéaire qu'en sRGB.
Le script et le futur
Comme j'ai toujours une confiance limitée dans ce genre d'automatismes, il me faut une validation manuelle avant de supprimer tous les fichiers intermédiaires.
Pour le reste, c'est ma façon habituelle de scripter du POSIX. Au cas où ça intéresse quelqu'un, voici la version courante dudit script.
Il faudrait que je mette ça dans un système de gestion de conf', mais j'ai un peu la flemme.
D'ailleurs dans la todo-list, ce serait sympa' de faire une détection automagique du périphérique, au lieu de coder son adresse en dur dans le script.
J'ai fait quelques expérimentations avec tesseract, mais je n'ai pas encore de façon satisfaisante de l'intégrer.
Et puis surtout, il faut que je fasse quelque chose de tous les PDF ainsi générés, avec de la réplication automatique et du chiffrement et tout le bazar.
Commentaires
1. Le mercredi 10 juin 2020 à 21:15, par _FrnchFrgg_ :
Perso, j'ai récemment du écrire un "script" ImageMagick pour corriger les photos de copies prises par les élèves. Ça donne ça:
pdfimages -all "$x" ttt for i in ttt*; do size="$(convert "$i" -format "%[fx:int(w/max(max(w/2000,h/2000),1))]x%[fx:int(h/max(max(w/2000,h/2000),1))]" info:)" convert "$i" -resize 25x25! \ "$i" -resize "$size!" \ -fx "0.98*v - u + 1" -normalize \ "$i.ppm" done convert *.ppm -unsharp 6x3 -page A4 -density 72 -compress jpeg -quality 20 out/"$x"L'idée est de soustraire à l'image une version très floutée (par un hack resize down and up parce que sinon c'est horriblement lent) d'elle même, pour normaliser le fond qui évidemment est très peu uniforme dans une photo prise n'importe comment par un élève. Ça ne fonctionne pas s'il y a des aplats de couleurs qui font partie du signal, bien entendu.
Cela dit, je trouve ça étrange que ton scanner te donne un fond qui n'est pas uniforme. Mon scanner (d'entrée de gamme, encore une fois), donne un résultat nettement meilleur et nettement plus uniforme, même en mettant des réglages de luminosité et de contraste qui n'écrasent pas le blanc de la feuille (et les autres détails très clairs par la même occasion).
Il y a un léger tremblottage du grain, bas de gamme oblige, mais à 300ppp un flou anisotropique très subtil corrige ça sans même perdre le grain des crayons graphite ou des bic (dans Gimp c'est "mean curvature blur", je ne sais pas ce qui correspond dans ImageMagick).
Franchement, le problème de décalage des couleurs m'aurait fait jeter l'éponge et passer à un autre matériel. Je trouve qu'on est loin des problèmes acceptables.
2. Le mercredi 10 juin 2020 à 21:19, par un anonyme :
Ah, et tesseract ça commence à envoyer du steak depuis qu'ils ont un réseau neuronal pour la reconnaissance. Ton idée c'est quoi ? Extraire suffisamment de texte pour les méta-données ? Récupérer un maximum ? tesseract a une sortie "pdf", il faudrait voir si on peut lui faire garder l'image et mettre le texte derrière (ou devant et invisible) pour pouvoir sélectionner et copier-coller, ou faire de la recherche en plein texte.
3. Le samedi 13 juin 2020 à 11:32, par Natacha :
Que désignes-tu exactement par « un fond pas uniforme » ?
La bande horizontale bleue en bas, et deux autres grisâtres à peu près à la hauteur des motifs noirs, ne sont pas des défauts du scanner mais des défauts de l'imprimante.
La mire qui a été scannée comme tests pour ce billet a été générée pour diagnostiquer un problème sur mon imprimante : quand j'imprime avec de la couleur, j'ai des fantômes des motifs colorés plus haut et plus bas (comme si le cylindre était mal réinitialisé, sauf que ça le fait vers le haut aussi) et de la couleur qui n'a rien à faire là, comme les deux barres en question.
Sur du papier vraiment blanc, et non pas sali par une imprimante laser défectueuse, je n'ai pas l'impression d'avoir constaté de non-homogénéité, mais je peux fabriquer un exemple si tu veux confirmer.
Ou alors c'est sur le « contrat » que tu trouves de la non-homogénéité ?
Et qu'est-ce que le « tremblotage du grain » ?
Enfin sur tessarct, j'ai été impressionnée par la performance de la reconnaissance, mais j'avoue que je ne sais pas encore trop quoi en faire, ça fait partie des choses sur lesquelles je dois encore réfléchir.
Il sait produire des PDF avec l'image originale et un texte invisible, cherchable et copier/collable. Enfin je me demande si c'est l'image originale ou une image réencodée, mon script utilise pour l'instant
img2pdfjustement parce qu'il est capable d'inclure des fichires JPEG sans les réencoder, et je ne mesure pas trop les inconvénients d'un réencodage supplémentaire dans ma chaîne.Pour l'instant le besoin principal que j'image est la recherche de texte dans une base de donnée documentaire, j'adorerais pouvoir
grep -rmais je crains que les documents de s'y prêtent pas, donc il faudrait d'abord trouver un moteur de recherche avant de réfléchir à ce qu'on peut lui faire manger.Il y a quelques documents dont j'aurais bien aimé avoir une représentation textuelle, pas au point de l'ASCII-art mais avec le texte placé à sa place, en supposant une police à espacement fixe de tailles données. Je n'ai cependant pas trouvé comment faire faire ça à tesseract.
4. Le lundi 22 juin 2020 à 22:37, par _FrnchFrgg_ :
J'utilise pdfjam pour transformer du jpeg en pdf, c'est en fait basé sur TεX. Et de manière surprenante, il optimise sacrément bien, même sans réencoder les images (sa compression des streams doit être meilleure ?). Même avec du PNG, j'obtiens le meilleur résultat en faisant "pdfjam" puis "pdfimages" (de poppler), puis de nouveau "pdfjam". Même jouer avec la compression de ImageMagick ne fait pas mieux.
Oui c'était le fond qui tirait vers le bleu, et qui semble être dégradé de haut en bas. Si c'est sur le scan d'origine, ça explique tout. Le "tremblottage du grain", c'est un peu comme si la i-ème ligne avait un décalage de (1+(-1)^i)/2 pixels, même si c'est pas tout à fait ça.
Pour le coup de faire une représentation textuelle fidèle, je suppose que c'est possible avec Tesseract, mais en passant par ce que je connais un coup de tesseract pour générer du PDF, puis pdftotext (toujours de poppler) avec l'option -layout pour préserver l'emplacement d'origine du texte (en supposant que ça marche bien).
Poster un commentaire
Autour de cette page

Autour de cet article
- Publié le 30 mai 2020 à 20h41
- État de la bête : retouchante
- 4 commentaire(s)
- Tag : Geek
Weblog
Derniers commentaires
- Vincent Bernat dans L'odeur de la fin
- Damien dans Les dangers de la théorie
- Head dans Infrastructure personnelle de stockage numérique
- Head dans Mes opinions sur l'IA
- Damien dans Ricing
- Mauvaisours dans En vrac 12
- Natacha dans En vrac 12
- raphael dans En vrac 12
- Balise dans En vrac 12
- Natacha dans Informatique personnelle distribuée
Tags
- (Sans tag) (6)
- Appel au public (19)
- Autoexploration (73)
- BSD (6)
- Boulot (31)
- Création (12)
- En vrac (13)
- Évènement (74)
- Geek (52)
- Goûts (13)
- Humeur (21)
- Inventaire (9)
- Jeux (7)
- Jouets (40)
- Lecture (11)
- Réflexion (26)
- Site (25)
- Social (27)
- Société (14)
- Suite (16)
- Vision atypique (35)
- Vœux (8)
Archives
- 2026 (7)
- 2025 (13)
- 2024 (14)
- 2023 (14)
- 2022 (14)
- 2021 (15)
- 2020 (14)
- Décembre 2020 (1)
- Novembre 2020 (2)
- Octobre 2020 (1)
- Septembre 2020 (1)
- Août 2020 (1)
- Juillet 2020 (1)
- Juin 2020 (1)
- Mai 2020 (1)
- Avril 2020 (2)
- Mars 2020 (1)
- Février 2020 (1)
- Janvier 2020 (1)
- 2019 (12)
- 2018 (12)
- 2017 (13)
- 2016 (16)
- 2015 (12)
- 2014 (13)
- 2013 (15)
- 2012 (18)
- 2011 (18)
- 2010 (20)
- 2009 (45)
